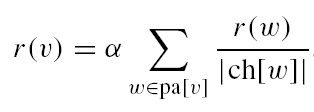
S2WC2, un Framework pour la Segmentation de Sessions Web Coté Client
Chapitre 4 – S2WC2, un Framework pour la Segmentation de Sessions Web Coté Client
4.1 Introduction
Après avoir exploré les sujets de l’extraction de connaissances et de la fouille du web et présenté l’état de l’art sur le web usage mining, nous décrivons dans ce chapitre notre approche pour la construction d’un framework de segmentation de sessions web de coté des utilisateurs. Nous y présentons l’architecture proposée, les différents choix que nous avons été amené à adopter, ainsi que les modules implémentés.
4.2 Architecture
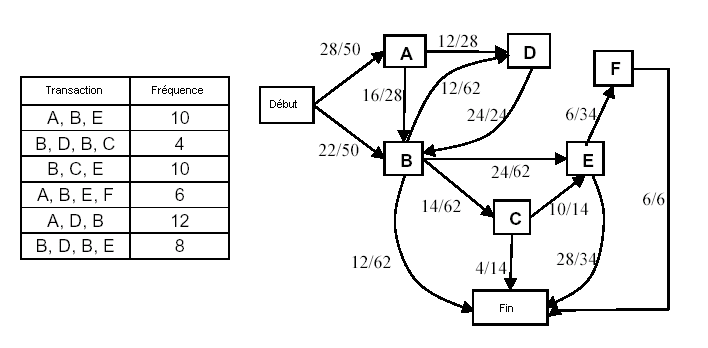
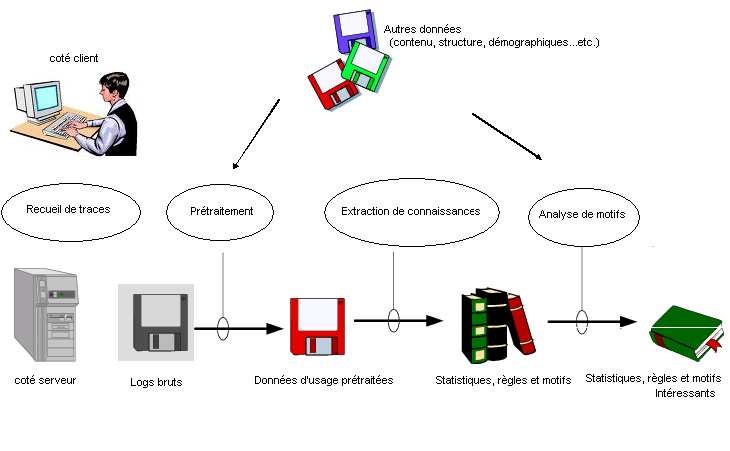
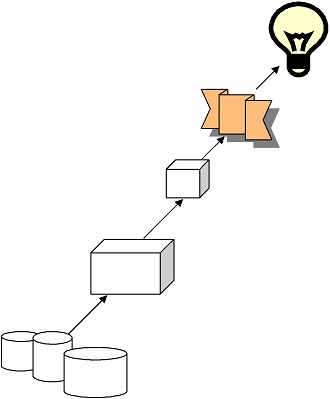
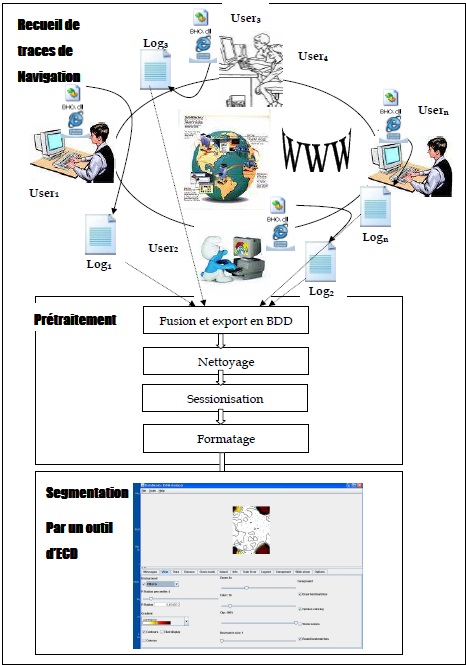
L’environnement conçu est constitué, de manière similaire à tout projet de fouille de données, de trois parties relativement distinctes les unes des autres : un collecteur de traces de navigation, une application de prétraitement de données, et un module d’extraction de connaissances. Cette architecture est illustrée dans la figure ci-après.
La collecte de traces de navigation est assurée par un module léger développé pour Internet Explorer de Microsoft, le navigateur le plus répandu. Cet outil, détaillé dans le point suivant, fournit des logs à ramasser sur les postes des utilisateurs ayant répondu favorablement à notre sollicitation et accepté de participer à l’étude.
La deuxième partie inclut plusieurs algorithmes que nous avons écrit afin de préparer les logs bruts des utilisateurs générés par l’outil de collecte de traces. Elle a consisté globalement, après la fusion des logs ramassés, à les nettoyer, d’en reconstituer les sessions, et