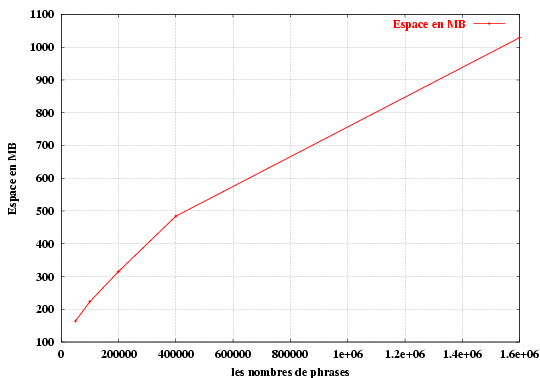
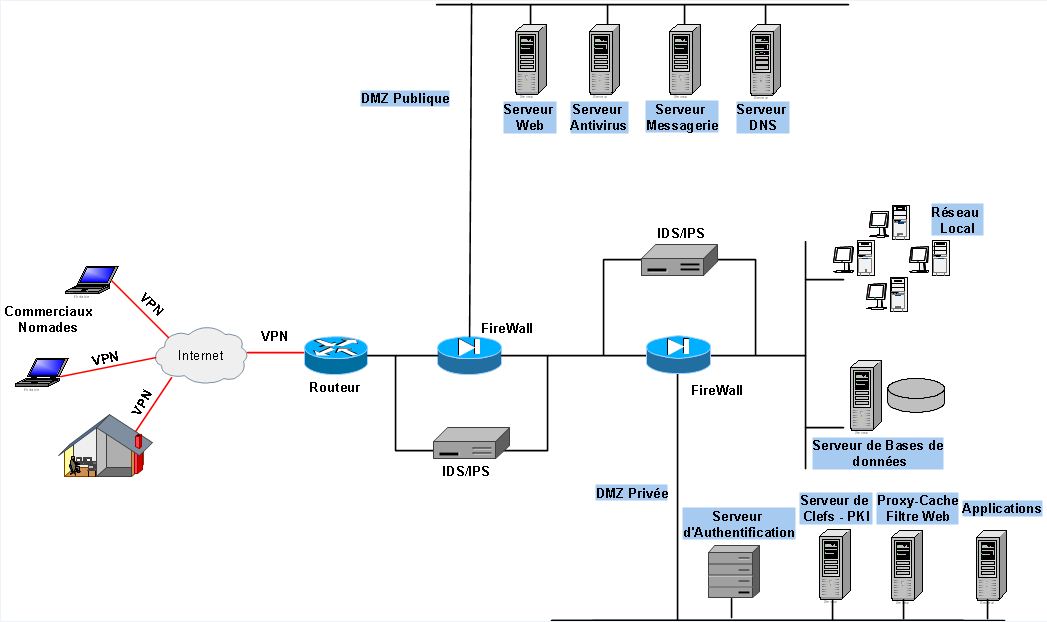
2.3 Protocoles utilisés pour réaliser une connexion VPN
2.3.1 Le protocole IPSEC
IPSEC, définit par la RFC 2401 (www.frameip.com/rfc/rfc2401.php), est un protocole qui vise à sécuriser l’échange de données au niveau de la couche réseau. Le réseau IPV4 étant largement déployé et la migration vers IPV6 étant inévitable, mais néanmoins longue, il est apparu intéressant de développer des techniques de protection des données communes à IPV4 et IPV6. Ces mécanismes sont couramment désignés par le terme IPSEC pour IP Security Protocols.
IPSEC est basé sur deux mécanismes. Le premier, AH, pour Authentication Header vise à assurer l’intégrité et l’authenticité des datagrammes IP. Il ne fournit par contre aucune confidentialité : les données fournies et transmises par ce protocole ne sont pas encodées.
Le second, ESP, pour Encapsulating Security Payload peut aussi permettre l’authentification des données mais est principalement utilisé pour le cryptage des informations. Bien qu’indépendants ces deux mécanismes sont presque toujours utilisés conjointement.
Enfin, le protocole IKE permet de gérer les échanges ou les associations entre protocoles de sécurité. Avant de décrire ces différents protocoles, nous allons exposer les différents éléments utilisés dans IPSEC.
Les mécanismes mentionnés ci-dessus font bien sûr appel à la cryptographie et utilisent donc un certain nombre de paramètres (algorithmes de chiffrement utilisés, clefs,


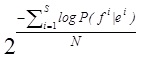 (4.1)
(4.1)